
In heutigen Computersystemen werden täglich Millionen von Datensätzen generiert. Dazu gehören Ihre Finanztransaktionen, das Aufgeben einer Bestellung oder Daten von Ihrem Autosensor. Um diese Daten-Streaming-Ereignisse in Echtzeit zu verarbeiten und Ereignisaufzeichnungen zuverlässig zwischen verschiedenen Unternehmenssystemen zu verschieben, benötigen Sie Folgendes Apache Kafka.
Apache Kafka ist eine Open-Source-Datenstreaming-Lösung, die über 1 Million Datensätze pro Sekunde verarbeitet. Neben diesem hohen Durchsatz bietet Apache Kafka hohe Skalierbarkeit und Verfügbarkeit, geringe Latenz und permanenten Speicher.
Unternehmen wie LinkedIn, Uber und Netflix verlassen sich bei der Echtzeitverarbeitung und dem Datenstreaming auf Apache Kafka. Der einfachste Weg, mit Apache Kafka zu beginnen, besteht darin, es auf Ihrem lokalen Computer zu installieren und auszuführen. Dadurch können Sie nicht nur den Apache Kafka-Server in Aktion sehen, sondern auch Nachrichten erstellen und konsumieren.

Mit praktischer Erfahrung im Starten des Servers, Erstellen von Themen und Schreiben von Java-Code mit dem Kafka-Client sind Sie bereit, Apache Kafka zu verwenden, um alle Ihre Datenpipeline-Anforderungen zu erfüllen.
How to Download Apache Kafka on your local machine
Sie können die neueste Version von Apache Kafka herunterladen offizielle Links. Der heruntergeladene Inhalt wird komprimiert .tgz Format. Nach dem Herunterladen müssen Sie es extrahieren.
Wenn Sie Linux verwenden, öffnen Sie Ihr Terminal. Navigieren Sie als Nächstes zu dem Speicherort, an dem Sie die komprimierte Version von Apache Kafka heruntergeladen haben. Führen Sie den folgenden Befehl aus:
tar -xzvf kafka_2.13-3.5.0.tgzNachdem der Befehl abgeschlossen ist, werden Sie feststellen, dass ein neues Verzeichnis mit dem Namen „ kafka_2.13-3.5.0. Navigieren Sie innerhalb des Ordners mit:
cd kafka_2.13-3.5.0Sie können nun den Inhalt dieses Verzeichnisses mit auflisten ls Befehl.
Für Windows-Benutzer können Sie die gleichen Schritte ausführen. Wenn Sie das nicht finden können tar Befehl können Sie ein Drittanbieter-Tool verwenden, z WinZip um das Archiv zu öffnen.
How to start Apache Kafka on your local machine
Nachdem Sie Apache Kafka heruntergeladen und extrahiert haben, ist es an der Zeit, es auszuführen. Es gibt keine Installationsprogramme. Sie können es direkt über Ihre Befehlszeile oder Ihr Terminalfenster verwenden.
Bevor Sie mit Apache Kafka beginnen, stellen Sie sicher, dass Java 8+ auf Ihrem System installiert ist. Apache Kafka erfordert eine laufende Java-Installation.
# 1. Führen Sie den Apache Zookeeper-Server aus
Der erste Schritt besteht darin, Apache Zookeeper auszuführen. Sie erhalten es als Teil des Archivs vorab heruntergeladen. Es handelt sich um einen Dienst, der für die Verwaltung von Konfigurationen und die Bereitstellung der Synchronisierung für andere Dienste verantwortlich ist.
Sobald Sie sich in dem Verzeichnis befinden, in das Sie den Inhalt des Archivs extrahiert haben, führen Sie den folgenden Befehl aus:
Für Linux-Benutzer:
bin/zookeeper-server-start.sh config/zookeeper.propertiesFür Windows Benutzer:
bin/windows/zookeeper-server-start.bat config/zookeeper.properties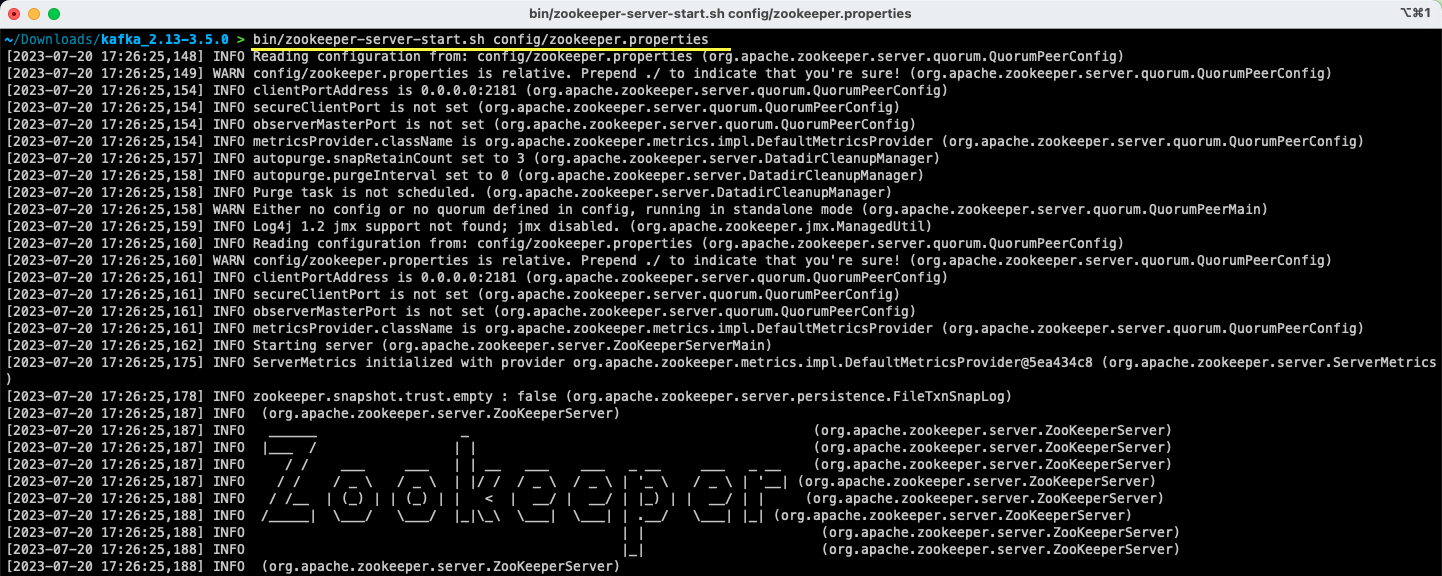
Die zookeeper.properties Die Datei enthält die Konfigurationen zum Ausführen des Apache Zookeeper-Servers. Sie können Eigenschaften wie das lokale Verzeichnis, in dem die Daten gespeichert werden, und den Port konfigurieren, auf dem der Server ausgeführt wird.
# 2. Starten Sie den Apache Kafka-Server
Nachdem der Apache Zookeeper-Server gestartet wurde, ist es an der Zeit, den Apache Kafka-Server zu starten.
Öffnen Sie ein neues Terminal- oder Eingabeaufforderungsfenster und navigieren Sie zu dem Verzeichnis, in dem sich die extrahierten Dateien befinden. Anschließend können Sie den Apache Kafka-Server mit dem folgenden Befehl starten:
Für Linux-Benutzer:
bin/kafka-server-start.sh config/server.propertiesFür Windows Benutzer:
bin/windows/kafka-server-start.bat config/server.propertiesIhr Apache Kafka-Server läuft. Falls Sie die Standardkonfiguration ändern möchten, können Sie dies tun, indem Sie die ändern server.properties Datei. Die verschiedenen Werte sind in der vorhanden offizielle Dokumentation.
How to Use Apache Kafka on your local machine
Sie können nun Apache Kafka auf Ihrem lokalen Computer verwenden, um Nachrichten zu erstellen und zu konsumieren. Da die Server Apache Zookeeper und Apache Kafka in Betrieb sind, sehen wir uns an, wie Sie Ihr erstes Thema erstellen, Ihre erste Nachricht produzieren und diese konsumieren können.
Was sind die Schritte zum Erstellen eines Themas in Apache Kafka?
Bevor Sie Ihr erstes Thema erstellen, wollen wir verstehen, was ein Thema eigentlich ist. In Apache Kafka ist ein Thema ein logischer Datenspeicher, der beim Datenstreaming hilft. Betrachten Sie es als den Kanal, über den Daten von einer Komponente zur anderen transportiert werden.
Ein Thema unterstützt Multi-Produzenten und Multi-Konsumenten – mehr als ein System kann aus einem Thema schreiben und lesen. Im Gegensatz zu anderen Nachrichtensystemen kann jede Nachricht aus einem Thema mehr als einmal konsumiert werden. Darüber hinaus können Sie auch die Aufbewahrungsdauer Ihrer Nachrichten angeben.
Nehmen wir das Beispiel eines Systems (Produzenten), das Daten für Banktransaktionen produziert. Und ein anderes System (Verbraucher) verbraucht diese Daten und sendet eine App-Benachrichtigung an den Benutzer. Um dies zu ermöglichen, ist ein Thema erforderlich.
Öffnen Sie ein neues Terminal- oder Eingabeaufforderungsfenster und navigieren Sie zu dem Verzeichnis, in das Sie das Archiv extrahiert haben. Der folgende Befehl erstellt ein Thema namens transactions:
Für Linux-Benutzer:
bin/kafka-topics.sh --create --topic transactions --bootstrap-server localhost:9092Für Windows Benutzer:
bin/windows/kafka-topics.bat --create --topic transactions --bootstrap-server localhost:9092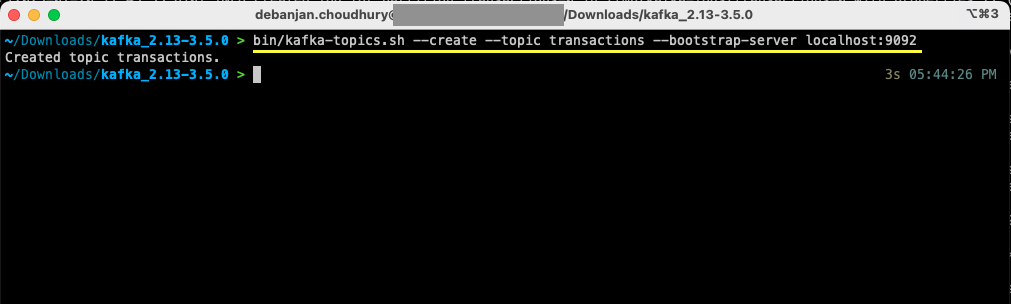
Sie haben jetzt Ihr erstes Thema erstellt und können mit der Erstellung und Nutzung von Nachrichten beginnen.
Wie erstelle ich eine Nachricht an Apache Kafka?
Wenn Ihr Apache Kafka-Thema fertig ist, können Sie jetzt Ihre erste Nachricht verfassen. Öffnen Sie ein neues Terminal- oder Eingabeaufforderungsfenster oder verwenden Sie dasselbe, mit dem Sie das Thema erstellt haben. Stellen Sie als Nächstes sicher, dass Sie sich im richtigen Verzeichnis befinden, in das Sie den Inhalt des Archivs extrahiert haben. Mit dem folgenden Befehl können Sie über die Befehlszeile Ihre Nachricht zum Thema verfassen:
Für Linux-Benutzer:
bin/kafka-console-producer.sh --topic transactions --bootstrap-server localhost:9092Für Windows Benutzer:
bin/windows/kafka-console-producer.bat --topic transactions --bootstrap-server localhost:9092Sobald Sie den Befehl ausführen, werden Sie sehen, dass Ihr Terminal- oder Eingabeaufforderungsfenster auf eine Eingabe wartet. Schreiben Sie Ihre erste Nachricht und drücken Sie die Eingabetaste.
> This is a transactional record for $100
Sie haben Ihre erste Nachricht an Apache Kafka auf Ihrem lokalen Computer erstellt. Anschließend können Sie diese Nachricht jetzt lesen.
Wie konsumiere ich eine Nachricht von Apache Kafka?
Vorausgesetzt, dass Ihr Thema erstellt wurde und Sie eine Nachricht zu Ihrem Kafka-Thema erstellt haben, können Sie diese Nachricht jetzt konsumieren.
Mit Apache Kafka können Sie mehrere Verbraucher demselben Thema zuordnen. Jeder Verbraucher kann Teil einer Verbrauchergruppe sein – eine logische Kennung. Wenn Sie beispielsweise über zwei Dienste verfügen, die dieselben Daten verbrauchen müssen, können diese unterschiedliche Verbrauchergruppen haben.
Wenn Sie jedoch über zwei Instanzen desselben Dienstes verfügen, möchten Sie vermeiden, dass dieselbe Nachricht zweimal konsumiert und verarbeitet wird. In diesem Fall haben beide die gleiche Verbrauchergruppe.
Stellen Sie im Terminal- oder Eingabeaufforderungsfenster sicher, dass Sie sich im richtigen Verzeichnis befinden. Verwenden Sie den folgenden Befehl, um den Consumer zu starten:
Für Linux-Benutzer:
bin/kafka-console-consumer.sh --topic transactions --from-beginning --bootstrap-server localhost:9092 --group notif-consumerFür Windows Benutzer:
bin/windows/kafka-console-consumer.bat --topic transactions --from-beginning --bootstrap-server localhost:9092 --group notif-consumer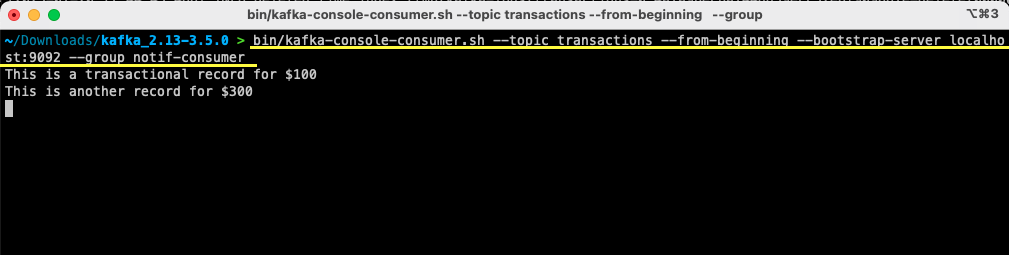
Die zuvor erstellte Nachricht wird auf Ihrem Terminal angezeigt. Sie haben jetzt Apache Kafka verwendet, um Ihre erste Nachricht zu konsumieren.
Die kafka-console-consumer Der Befehl benötigt viele übergebene Argumente. Sehen wir uns an, was jedes einzelne davon bedeutet:
- Die
--topicerwähnt das Thema, von dem aus Sie konsumieren werden --from-beginningweist den Konsolenkonsumenten an, ab der ersten vorhandenen Nachricht mit dem Lesen von Nachrichten zu beginnen- Ihr Apache Kafka-Server wird über erwähnt
--bootstrap-serverzu erhalten - Darüber hinaus können Sie die Verbrauchergruppe erwähnen, indem Sie Folgendes übergeben
--groupParameter - Wenn kein Verbrauchergruppenparameter vorhanden ist, wird er automatisch generiert
Während der Konsolenkonsument läuft, können Sie versuchen, neue Nachrichten zu erstellen. Sie werden sehen, dass alle verbraucht sind und in Ihrem Terminal angezeigt werden.
Nachdem Sie nun Ihr Thema erstellt und erfolgreich Nachrichten erstellt und konsumiert haben, integrieren wir dies in eine Java-Anwendung.
How to create Apache Kafka producer and consumer using Java
Bevor Sie beginnen, stellen Sie sicher, dass Java 8+ auf Ihrem lokalen Computer installiert ist. Apache Kafka bietet eine eigene Client-Bibliothek, die Ihnen eine nahtlose Verbindung ermöglicht. Wenn Sie Maven zum Verwalten Ihrer Abhängigkeiten verwenden, fügen Sie die folgende Abhängigkeit zu Ihrer hinzu pom.xml
<dependency>
<groupId>org.apache.kafka</groupId>
<artifactId>kafka-clients</artifactId>
<version>3.5.0</version>
</dependency>Sie können die Bibliothek auch von herunterladen Maven-Repository und fügen Sie es Ihrem Java-Klassenpfad hinzu.
Sobald Ihre Bibliothek eingerichtet ist, öffnen Sie einen Code-Editor Ihrer Wahl. Sehen wir uns an, wie Sie Ihren Produzenten und Verbraucher mit Java starten können.
Erstellen Sie einen Apache Kafka Java-Produzenten
Mit der kafka-clients Nachdem Sie die Bibliothek eingerichtet haben, können Sie nun mit der Erstellung Ihres Kafka-Produzenten beginnen.
Erstellen wir eine Klasse namens SimpleProducer.java. Dieser wird für die Erstellung von Nachrichten o. ä. zuständig seinn das Thema, das Sie zuvor erstellt haben. Innerhalb dieser Klasse erstellen Sie eine Instanz von org.apache.kafka.clients.producer.KafkaProducer. Anschließend verwenden Sie diesen Produzenten zum Versenden Ihrer Nachrichten.
Zum Erstellen des Kafka-Produzenten benötigen Sie den Host und den Port Ihres Apache Kafka-Servers. Da Sie es auf Ihrem lokalen Computer ausführen, wird es der Host sein localhost. Vorausgesetzt, Sie haben die Standardeigenschaften beim Starten des Servers nicht geändert, bleibt der Port bestehen 9092. Betrachten Sie den folgenden Code, der Ihnen beim Erstellen Ihres Produzenten hilft:
package org.example.kafka;
import org.apache.kafka.clients.producer.KafkaProducer;
import org.apache.kafka.clients.producer.ProducerConfig;
import org.apache.kafka.clients.producer.ProducerRecord;
import org.apache.kafka.clients.producer.RecordMetadata;
import org.apache.kafka.common.serialization.StringSerializer;
import java.util.Properties;
import java.util.concurrent.ExecutionException;
import java.util.concurrent.Future;
public class SimpleProducer {
private final KafkaProducer<String, String> producer;
public SimpleProducer(String host, String port) {
String server = host + ":" + port;
Properties properties = new Properties();
properties.setProperty(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, server);
properties.setProperty(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, StringSerializer.class.getName());
properties.setProperty(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG, StringSerializer.class.getName());
this.producer = new KafkaProducer<>(properties);
}
}Sie werden feststellen, dass drei Eigenschaften festgelegt werden. Lassen Sie uns jeden einzelnen kurz durchgehen:
- Mit BOOTSTRAP_SERVERS_CONFIG können Sie definieren, wo der Apache Kafka-Server ausgeführt wird
- KEY_SERIALIZER_CLASS_CONFIG teilt dem Produzenten mit, welches Format zum Senden der Nachrichtenschlüssel verwendet werden soll.
- Das Format zum Senden der eigentlichen Nachricht wird mithilfe der Eigenschaft VALUE_SERIALIZER_CLASS_CONFIG definiert.
Da Sie Textnachrichten senden, sind beide Eigenschaften auf „Verwenden“ eingestellt StringSerializer.class.
Um tatsächlich eine Nachricht an Ihr Thema zu senden, müssen Sie das verwenden producer.send() Methode, die ein übernimmt ProducerRecord. Mit dem folgenden Code erhalten Sie eine Methode, die eine Nachricht an das Thema sendet und die Antwort zusammen mit dem Nachrichtenoffset ausgibt.
public void produce(String topic, String message) throws ExecutionException, InterruptedException {
ProducerRecord<String, String> record = new ProducerRecord<>(topic, message);
final Future<RecordMetadata> send = this.producer.send(record);
final RecordMetadata recordMetadata = send.get();
System.out.println(recordMetadata);
}Wenn der gesamte Code vorhanden ist, können Sie nun Nachrichten an Ihr Thema senden. Sie können a verwenden main Methode, um dies zu testen, wie im folgenden Code dargestellt:
package org.example.kafka;
import org.apache.kafka.clients.producer.KafkaProducer;
import org.apache.kafka.clients.producer.ProducerConfig;
import org.apache.kafka.clients.producer.ProducerRecord;
import org.apache.kafka.clients.producer.RecordMetadata;
import org.apache.kafka.common.serialization.StringSerializer;
import java.util.Properties;
import java.util.concurrent.ExecutionException;
import java.util.concurrent.Future;
public class SimpleProducer {
private final KafkaProducer<String, String> producer;
public SimpleProducer(String host, String port) {
String server = host + ":" + port;
Properties properties = new Properties();
properties.setProperty(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, server);
properties.setProperty(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, StringSerializer.class.getName());
properties.setProperty(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG, StringSerializer.class.getName());
this.producer = new KafkaProducer<>(properties);
}
public void produce(String topic, String message) throws ExecutionException, InterruptedException {
ProducerRecord<String, String> record = new ProducerRecord<>(topic, message);
final Future<RecordMetadata> send = this.producer.send(record);
final RecordMetadata recordMetadata = send.get();
System.out.println(recordMetadata);
}
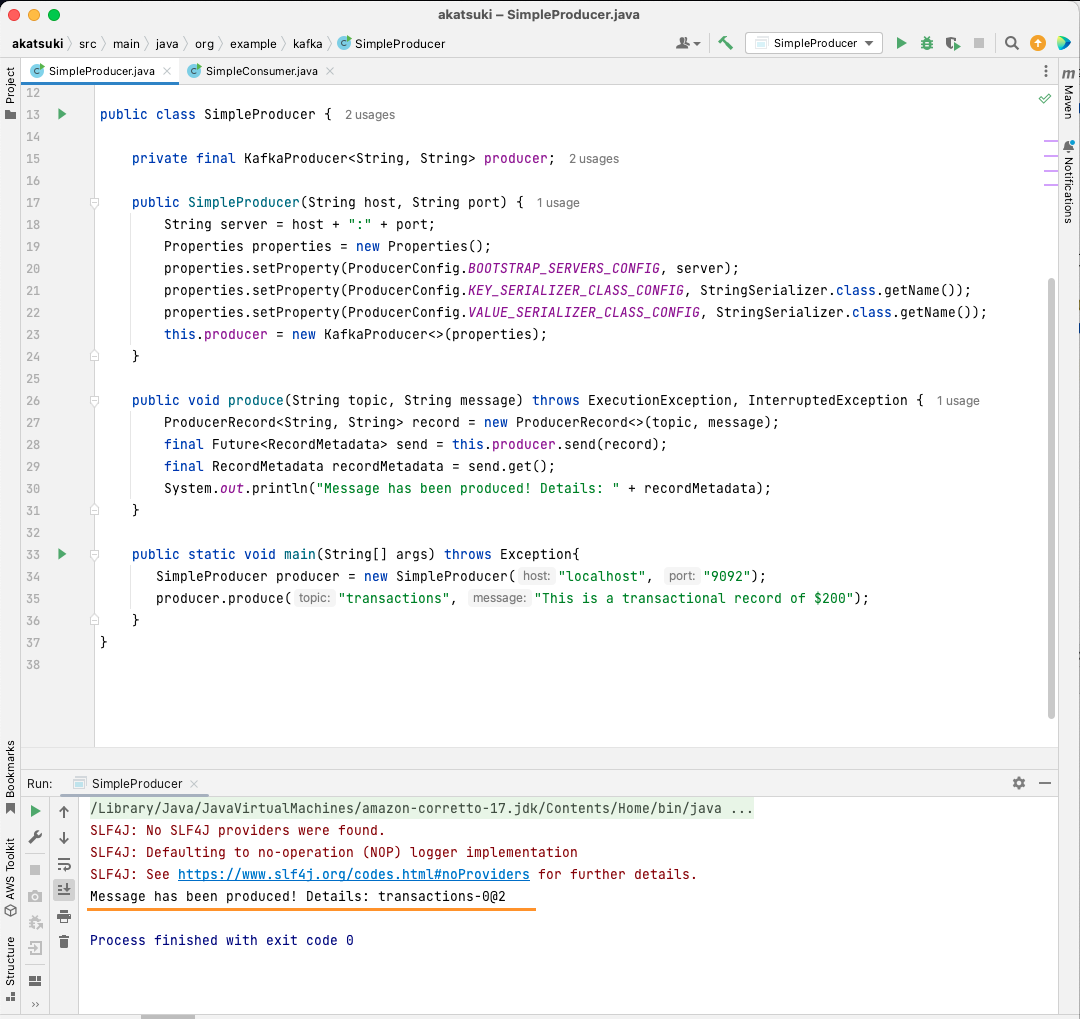
public static void main(String[] args) throws Exception{
SimpleProducer producer = new SimpleProducer("localhost", "9092");
producer.produce("transactions", "This is a transactional record of $200");
}
}
In diesem Code erstellen Sie eine SimpleProducer das eine Verbindung zu Ihrem Apache Kafka-Server auf Ihrem lokalen Computer herstellt. Es verwendet intern die KafkaProducer um Textnachrichten zu Ihrem Thema zu verfassen.
Erstellen Sie einen Apache Kafka Java-Consumer
Es ist an der Zeit, mithilfe des Java-Clients einen Apache Kafka-Konsumenten zu erstellen. Erstellen Sie eine Klasse namens SimpleConsumer.java. Als Nächstes erstellen Sie einen Konstruktor für diese Klasse, der die Klasse initialisiert org.apache.kafka.clients.consumer.KafkaConsumer. Zum Erstellen des Consumers benötigen Sie den Host und den Port, auf dem der Apache Kafka-Server läuft. Darüber hinaus benötigen Sie die Verbrauchergruppe sowie das Thema, von dem Sie konsumieren möchten. Verwenden Sie den unten angegebenen Codeausschnitt:
package org.example.kafka;
import org.apache.kafka.clients.consumer.ConsumerConfig;
import org.apache.kafka.clients.consumer.ConsumerRecords;
import org.apache.kafka.clients.consumer.KafkaConsumer;
import org.apache.kafka.common.serialization.StringDeserializer;
import java.time.Duration;
import java.util.List;
import java.util.Properties;
import java.util.concurrent.atomic.AtomicBoolean;
public class SimpleConsumer {
private static final String OFFSET_RESET = "earliest";
private final KafkaConsumer<String, String> consumer;
private boolean keepConsuming = true;
public SimpleConsumer(String host, String port, String consumerGroupId, String topic) {
String server = host + ":" + port;
Properties properties = new Properties();
properties.setProperty(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG, server);
properties.setProperty(ConsumerConfig.GROUP_ID_CONFIG, consumerGroupId);
properties.setProperty(ConsumerConfig.AUTO_OFFSET_RESET_CONFIG, OFFSET_RESET);
properties.setProperty(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class.getName());
properties.setProperty(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class.getName());
this.consumer = new KafkaConsumer<>(properties);
this.consumer.subscribe(List.of(topic));
}
}Ähnlich wie der Kafka Producer nimmt auch der Kafka Consumer ein Properties-Objekt auf. Schauen wir uns die verschiedenen Eigenschaftensätze an:
- BOOTSTRAP_SERVERS_CONFIG teilt dem Verbraucher mit, wo der Apache Kafka-Server ausgeführt wird
- Die Verbrauchergruppe wird mithilfe der GROUP_ID_CONFIG erwähnt
- Wenn der Verbraucher mit dem Konsumieren beginnt, können Sie mit AUTO_OFFSET_RESET_CONFIG angeben, ab wann Sie mit dem Konsumieren von Nachrichten beginnen möchten
- KEY_DESERIALIZER_CLASS_CONFIG teilt dem Verbraucher den Typ des Nachrichtenschlüssels mit
- VALUE_DESERIALIZER_CLASS_CONFIG gibt den Verbrauchertyp der tatsächlichen Nachricht an
Da Sie in Ihrem Fall Textnachrichten konsumieren, sind die Eigenschaften des Deserialisierers auf eingestellt StringDeserializer.class.
Sie werden nun die Nachrichten aus Ihrem Thema konsumieren. Der Einfachheit halber drucken Sie die Nachricht, sobald sie verarbeitet wurde, auf der Konsole aus. Sehen wir uns an, wie Sie dies mit dem folgenden Code erreichen können:
private boolean keepConsuming = true;
public void consume() {
while (keepConsuming) {
final ConsumerRecords<String, String> consumerRecords = this.consumer.poll(Duration.ofMillis(100L));
if (consumerRecords != null && !consumerRecords.isEmpty()) {
consumerRecords.iterator().forEachRemaining(consumerRecord -> {
System.out.println(consumerRecord.value());
});
}
}
}Dieser Code fragt das Thema weiterhin ab. Wenn Sie einen Verbraucherdatensatz erhalten, wird die Nachricht gedruckt. Testen Sie Ihren Verbraucher mithilfe einer Hauptmethode in Aktion. Sie starten eine Java-Anwendung, die das Thema weiterhin verarbeitet und die Nachrichten druckt. Stoppen Sie die Java-Anwendung, um den Verbraucher zu beenden.
package org.example.kafka;
import org.apache.kafka.clients.consumer.ConsumerConfig;
import org.apache.kafka.clients.consumer.ConsumerRecords;
import org.apache.kafka.clients.consumer.KafkaConsumer;
import org.apache.kafka.common.serialization.StringDeserializer;
import java.time.Duration;
import java.util.List;
import java.util.Properties;
import java.util.concurrent.atomic.AtomicBoolean;
public class SimpleConsumer {
private static final String OFFSET_RESET = "earliest";
private final KafkaConsumer<String, String> consumer;
private boolean keepConsuming = true;
public SimpleConsumer(String host, String port, String consumerGroupId, String topic) {
String server = host + ":" + port;
Properties properties = new Properties();
properties.setProperty(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG, server);
properties.setProperty(ConsumerConfig.GROUP_ID_CONFIG, consumerGroupId);
properties.setProperty(ConsumerConfig.AUTO_OFFSET_RESET_CONFIG, OFFSET_RESET);
properties.setProperty(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class.getName());
properties.setProperty(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class.getName());
this.consumer = new KafkaConsumer<>(properties);
this.consumer.subscribe(List.of(topic));
}
public void consume() {
while (keepConsuming) {
final ConsumerRecords<String, String> consumerRecords = this.consumer.poll(Duration.ofMillis(100L));
if (consumerRecords != null && !consumerRecords.isEmpty()) {
consumerRecords.iterator().forEachRemaining(consumerRecord -> {
System.out.println(consumerRecord.value());
});
}
}
}
public static void main(String[] args) {
SimpleConsumer simpleConsumer = new SimpleConsumer("localhost", "9092", "transactions-consumer", "transactions");
simpleConsumer.consume();
}
}
Wenn Sie den Code ausführen, werden Sie feststellen, dass er nicht nur die von Ihrem Java-Produzenten erzeugten Nachrichten verbraucht, sondern auch die, die Sie über den Konsolenproduzenten erzeugt haben. Dies liegt daran, dass die AUTO_OFFSET_RESET_CONFIG Die Eigenschaft wurde auf festgelegt earliest.
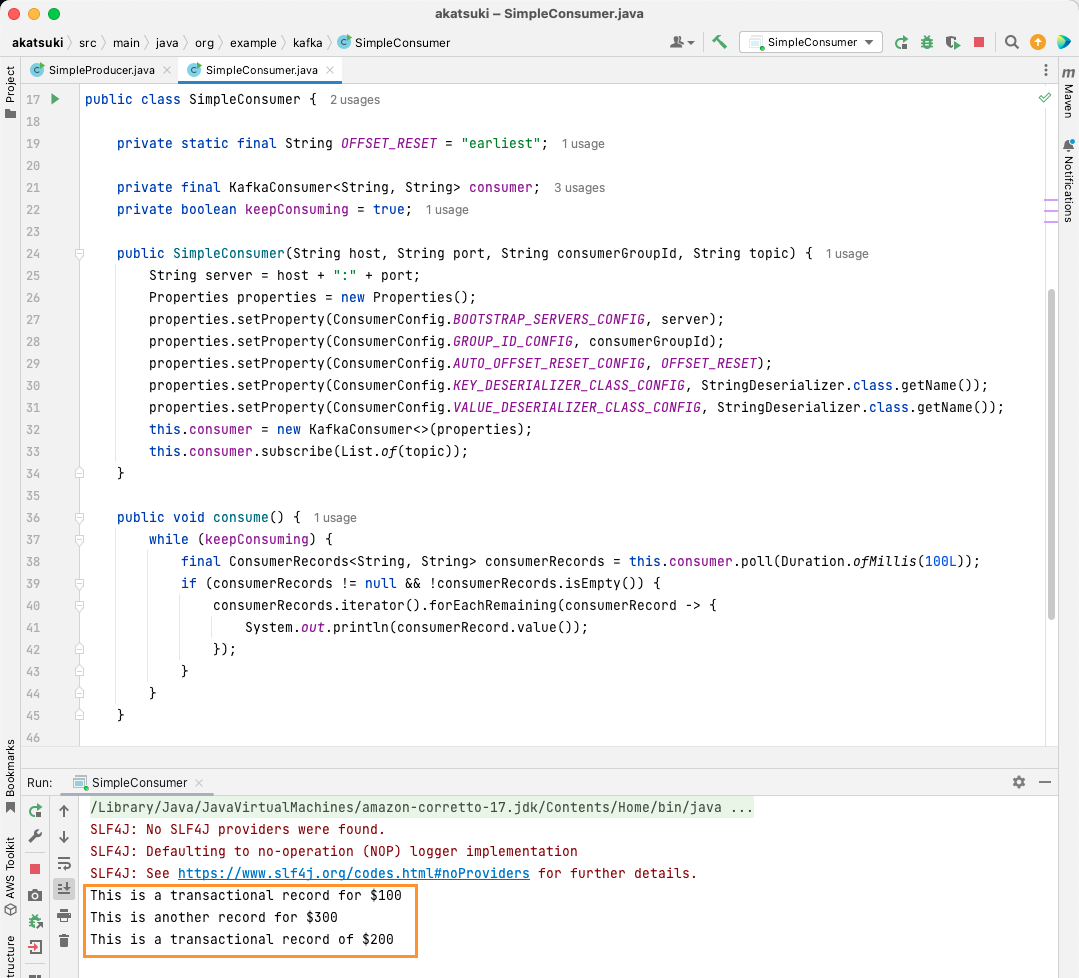
Wenn SimpleConsumer ausgeführt wird, können Sie den Konsolenproduzenten oder die SimpleProducer-Java-Anwendung verwenden, um weitere Nachrichten zum Thema zu erstellen. Sie werden sehen, wie sie auf der Konsole verbraucht und gedruckt werden.
Erfüllen Sie alle Ihre Datenpipeline-Anforderungen mit Apache Kafka
Mit Apache Kafka können Sie alle Ihre Datenpipeline-Anforderungen problemlos bewältigen. Mit der Einrichtung von Apache Kafka auf Ihrem lokalen Computer können Sie alle verschiedenen Funktionen erkunden, die Kafka bietet. Darüber hinaus können Sie mit dem offiziellen Java-Client effizient schreiben, eine Verbindung herstellen und mit Ihrem Apache Kafka-Server kommunizieren.
Als vielseitiges, skalierbares und hochleistungsfähiges Daten-Streaming-System kann Apache Kafka für Sie wirklich bahnbrechend sein. Sie können es für Ihre lokale Entwicklung nutzen oder sogar in Ihre Produktionssysteme integrieren. Genauso wie die lokale Einrichtung einfach ist, ist die Einrichtung von Apache Kafka für größere Anwendungen keine große Aufgabe.
Wenn Sie nach Daten-Streaming-Plattformen suchen, können Sie sich die ansehen beste Streaming-Datenplattformen für Echtzeitanalyse und -verarbeitung.







