
Miljoenen gegevensrecords worden elke dag gegenereerd in de huidige computersystemen. Denk hierbij aan uw financiële transacties, het plaatsen van een bestelling of gegevens van uw autosensor. Om deze datastreaminggebeurtenissen in realtime te verwerken en om op betrouwbare wijze gebeurtenisrecords tussen verschillende bedrijfssystemen te verplaatsen, hebt u Apache Kafka.
Apache Kafka is een open-source oplossing voor datastreaming die meer dan 1 miljoen records per seconde verwerkt. Naast deze hoge doorvoer biedt Apache Kafka hoge schaalbaarheid en beschikbaarheid, lage latentie en permanente opslag.
Bedrijven als LinkedIn, Uber en Netflix vertrouwen op Apache Kafka voor real-time verwerking en datastreaming. De eenvoudigste manier om met Apache Kafka aan de slag te gaan, is door het op uw lokale computer te laten werken. Hierdoor kunt u niet alleen de Apache Kafka-server in actie zien, maar kunt u ook berichten produceren en gebruiken.

Met praktische ervaring in het starten van de server, het maken van onderwerpen en het schrijven van Java-code met behulp van de Kafka-client, bent u klaar om Apache Kafka te gebruiken om aan al uw behoeften op het gebied van datapijplijnen te voldoen.
How to Download Apache Kafka on your local machine
U kunt de nieuwste versie van Apache Kafka downloaden van de officiële link. De gedownloade inhoud wordt gecomprimeerd in .tgz formaat. Eenmaal gedownload, moet je hetzelfde uitpakken.
Als je Linux bent, open dan je terminal. Navigeer vervolgens naar de locatie waar u de gecomprimeerde Apache Kafka-versie hebt gedownload. Voer de volgende opdracht uit:
tar -xzvf kafka_2.13-3.5.0.tgzNadat de opdracht is voltooid, zult u merken dat een nieuwe map wordt genoemd kafka_2.13-3.5.0. Navigeer in de map met:
cd kafka_2.13-3.5.0U kunt nu de inhoud van deze map weergeven met behulp van de ls opdracht.
Voor Windows-gebruikers kunt u dezelfde stappen volgen. Als u de tar opdracht, kunt u een hulpprogramma van derden gebruiken, zoals WinZip om het archief te openen.
How to start Apache Kafka on your local machine
Nadat je Apache Kafka hebt gedownload en uitgepakt, is het tijd om het uit te voeren. Het heeft geen installatieprogramma's. U kunt het direct gebruiken via uw opdrachtregel of terminalvenster.
Voordat u met Apache Kafka begint, moet u ervoor zorgen dat Java 8+ op uw systeem is geïnstalleerd. Apache Kafka vereist een actieve Java-installatie.
#1. Voer de Apache Zookeeper-server uit
De eerste stap is het uitvoeren van Apache Zookeeper. Je krijgt het vooraf gedownload als onderdeel van het archief. Het is een service die verantwoordelijk is voor het onderhouden van configuraties en het bieden van synchronisatie voor andere services.
Zodra u zich in de map bevindt waarin u de inhoud van het archief hebt uitgepakt, voert u de volgende opdracht uit:
Voor Linux-gebruikers:
bin/zookeeper-server-start.sh config/zookeeper.propertiesVoor Windows-gebruikers:
bin/windows/zookeeper-server-start.bat config/zookeeper.properties
Het zookeeper.properties -bestand biedt de configuraties voor het uitvoeren van de Apache Zookeeper-server. U kunt eigenschappen configureren zoals de lokale map waar de gegevens worden opgeslagen en de poort waarop de server draait.
#2. Start de Apache Kafka-server
Nu de Apache Zookeeper-server is gestart, is het tijd om de Apache Kafka-server te starten.
Open een nieuw terminal- of opdrachtpromptvenster en navigeer naar de map waar de uitgepakte bestanden aanwezig zijn. Vervolgens kunt u de Apache Kafka-server starten met behulp van de onderstaande opdracht:
Voor Linux-gebruikers:
bin/kafka-server-start.sh config/server.propertiesVoor Windows-gebruikers:
bin/windows/kafka-server-start.bat config/server.propertiesU heeft uw Apache Kafka-server actief. Als u de standaardconfiguratie wilt wijzigen, kunt u dit doen door de server.properties bestand. De verschillende waarden zijn aanwezig in de officiële documentatie.
How to Use Apache Kafka on your local machine
U bent nu klaar om Apache Kafka op uw lokale computer te gaan gebruiken om berichten te produceren en te gebruiken. Aangezien de Apache Zookeeper- en Apache Kafka-servers actief zijn, laten we eens kijken hoe u uw eerste onderwerp kunt maken, uw eerste bericht kunt produceren en hetzelfde kunt gebruiken.
Wat zijn de stappen om een onderwerp te maken in Apache Kafka?
Voordat u uw eerste onderwerp maakt, laten we begrijpen wat een onderwerp eigenlijk is. In Apache Kafka is een onderwerp een logische gegevensopslag die helpt bij het streamen van gegevens. Zie het als het kanaal waardoor gegevens van de ene component naar de andere worden getransporteerd.
Een onderwerp ondersteunt multi-producenten en multi-consumenten - meer dan één systeem kan schrijven en lezen van een onderwerp. In tegenstelling tot andere berichtensystemen kan elk bericht van een onderwerp meer dan eens worden geconsumeerd. Daarnaast kunt u ook de bewaartermijn van uw berichten vermelden.
Laten we het voorbeeld nemen van een systeem (producent) dat gegevens produceert voor banktransacties. En een ander systeem (consument) verbruikt deze data en stuurt een app-notificatie naar de gebruiker. Om dit te vergemakkelijken is een onderwerp vereist.
Open een nieuw terminal- of opdrachtpromptvenster en navigeer naar de map waarin u het archief hebt uitgepakt. Met de volgende opdracht wordt een onderwerp gemaakt met de naam transactions:
Voor Linux-gebruikers:
bin/kafka-topics.sh --create --topic transactions --bootstrap-server localhost:9092Voor Windows-gebruikers:
bin/windows/kafka-topics.bat --create --topic transactions --bootstrap-server localhost:9092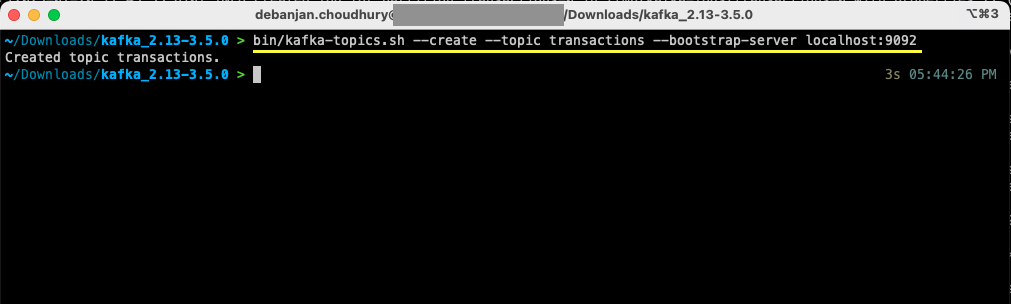
Je hebt nu je eerste onderwerp gemaakt en je bent klaar om berichten te produceren en te consumeren.
Hoe maak je een bericht naar Apache Kafka?
Met uw Apache Kafka-onderwerp gereed, kunt u nu uw eerste bericht produceren. Open een nieuw terminal- of opdrachtpromptvenster of gebruik hetzelfde venster dat u hebt gebruikt om het onderwerp te maken. Zorg er vervolgens voor dat u zich in de juiste map bevindt waar u de inhoud van het archief hebt uitgepakt. U kunt de opdrachtregel gebruiken om uw bericht over het onderwerp te produceren met behulp van de volgende opdracht:
Voor Linux-gebruikers:
bin/kafka-console-producer.sh --topic transactions --bootstrap-server localhost:9092Voor Windows-gebruikers:
bin/windows/kafka-console-producer.bat --topic transactions --bootstrap-server localhost:9092Nadat u de opdracht hebt uitgevoerd, ziet u dat uw terminal- of opdrachtpromptvenster wacht op invoer. Schrijf je eerste bericht en druk op Enter.
> This is a transactional record for $100
U hebt uw eerste bericht aan Apache Kafka op uw lokale computer geproduceerd. Vervolgens bent u nu klaar om dit bericht te consumeren.
Hoe een bericht van Apache Kafka te consumeren?
Op voorwaarde dat uw onderwerp is gemaakt en u een bericht hebt gemaakt voor uw Kafka-onderwerp, kunt u dat bericht nu gebruiken.
Met Apache Kafka kunt u meerdere consumenten aan hetzelfde onderwerp koppelen. Elke consument kan deel uitmaken van een consumentengroep – een logische identificatie. Als u bijvoorbeeld twee services hebt die dezelfde gegevens moeten verbruiken, kunnen ze verschillende consumentengroepen hebben.
Als u echter twee exemplaren van dezelfde service hebt, wilt u voorkomen dat u hetzelfde bericht twee keer gebruikt en verwerkt. Dan hebben ze allebei dezelfde consumentengroep.
Zorg ervoor dat u zich in de juiste map bevindt in het terminal- of opdrachtpromptvenster. Gebruik de volgende opdracht om de consument te starten:
Voor Linux-gebruikers:
bin/kafka-console-consumer.sh --topic transactions --from-beginning --bootstrap-server localhost:9092 --group notif-consumerVoor Windows-gebruikers:
bin/windows/kafka-console-consumer.bat --topic transactions --from-beginning --bootstrap-server localhost:9092 --group notif-consumer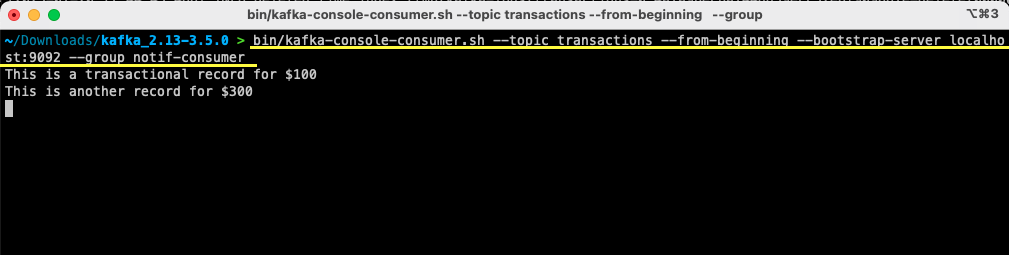
Je ziet het bericht dat je eerder hebt gemaakt verschijnen op je terminal. Je hebt nu Apache Kafka gebruikt om je eerste bericht te consumeren.
Het kafka-console-consumer opdracht neemt veel argumenten in beslag. Laten we eens kijken wat elk van hen betekent:
- Het
--topicvermeldt het onderwerp van waaruit u zult consumeren --from-beginningvertelt de consoleconsument om berichten te lezen vanaf het eerste aanwezige bericht- Uw Apache Kafka-server wordt vermeld via de
--bootstrap-serveroptie - Bovendien kunt u de consumentengroep vermelden door de
--groupparameter - Bij afwezigheid van een consumentengroepparameter wordt deze automatisch gegenereerd
Terwijl de consoleconsument draait, kunt u proberen nieuwe berichten te maken. U zult zien dat ze allemaal zijn verbruikt en in uw terminal verschijnen.
Nu je je onderwerp hebt gemaakt en met succes berichten hebt geproduceerd en geconsumeerd, laten we dit integreren met een Java-toepassing.
How to create Apache Kafka producer and consumer using Java
Voordat u begint, moet u ervoor zorgen dat Java 8+ op uw lokale computer is geïnstalleerd. Apache Kafka biedt zijn eigen clientbibliotheek waarmee u naadloos verbinding kunt maken. Als u Maven gebruikt om uw afhankelijkheden te beheren, voegt u de volgende afhankelijkheid toe aan uw pom.xml
<dependency>
<groupId>org.apache.kafka</groupId>
<artifactId>kafka-clients</artifactId>
<version>3.5.0</version>
</dependency>U kunt de bibliotheek ook downloaden van de Maven-opslagplaats en voeg het toe aan uw Java-klassenpad.
Zodra uw bibliotheek op zijn plaats staat, opent u een code-editor naar keuze. Laten we eens kijken hoe u uw producent en consument kunt opstarten met behulp van Java.
Creëer Apache Kafka Java-producer
Met de kafka-clients bibliotheek op zijn plaats, bent u nu klaar om te beginnen met het maken van uw Kafka-producer.
Laten we een klasse maken met de naam SimpleProducer.java. Dit zal verantwoordelijk zijn voor het produceren van berichten on het onderwerp dat u eerder hebt gemaakt. Binnen deze klasse maak je een instantie van org.apache.kafka.clients.producer.KafkaProducer. Vervolgens gebruik je deze producer om je berichten te versturen.
Voor het maken van de Kafka-producer hebt u de host en poort van uw Apache Kafka-server nodig. Aangezien u het op uw lokale computer uitvoert, zal de host dat zijn localhost. Aangezien u de standaardeigenschappen niet hebt gewijzigd bij het opstarten van de server, zal de poort dat wel zijn 9092. Overweeg de volgende code hieronder die u zal helpen bij het maken van uw producer:
package org.example.kafka;
import org.apache.kafka.clients.producer.KafkaProducer;
import org.apache.kafka.clients.producer.ProducerConfig;
import org.apache.kafka.clients.producer.ProducerRecord;
import org.apache.kafka.clients.producer.RecordMetadata;
import org.apache.kafka.common.serialization.StringSerializer;
import java.util.Properties;
import java.util.concurrent.ExecutionException;
import java.util.concurrent.Future;
public class SimpleProducer {
private final KafkaProducer<String, String> producer;
public SimpleProducer(String host, String port) {
String server = host + ":" + port;
Properties properties = new Properties();
properties.setProperty(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, server);
properties.setProperty(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, StringSerializer.class.getName());
properties.setProperty(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG, StringSerializer.class.getName());
this.producer = new KafkaProducer<>(properties);
}
}U zult merken dat er drie eigenschappen worden ingesteld. Laten we ze snel doornemen:
- Met de BOOTSTRAP_SERVERS_CONFIG kunt u bepalen waar de Apache Kafka-server wordt uitgevoerd
- De KEY_SERIALIZER_CLASS_CONFIG vertelt de producent welk formaat hij moet gebruiken voor het verzenden van de berichtsleutels.
- Het formaat voor het verzenden van het daadwerkelijke bericht wordt gedefinieerd met behulp van de eigenschap VALUE_SERIALIZER_CLASS_CONFIG.
Aangezien u sms-berichten gaat verzenden, zijn beide eigenschappen ingesteld om te gebruiken StringSerializer.class.
Om daadwerkelijk een bericht naar je onderwerp te sturen, moet je de producer.send() methode die rekening houdt met a ProducerRecord. De volgende code geeft je een methode die een bericht naar het onderwerp stuurt en het antwoord samen met de berichtoffset afdrukt.
public void produce(String topic, String message) throws ExecutionException, InterruptedException {
ProducerRecord<String, String> record = new ProducerRecord<>(topic, message);
final Future<RecordMetadata> send = this.producer.send(record);
final RecordMetadata recordMetadata = send.get();
System.out.println(recordMetadata);
}Met de volledige code op zijn plaats, kunt u nu berichten naar uw onderwerp sturen. U kunt een main methode om dit uit te testen, zoals weergegeven in de onderstaande code:
package org.example.kafka;
import org.apache.kafka.clients.producer.KafkaProducer;
import org.apache.kafka.clients.producer.ProducerConfig;
import org.apache.kafka.clients.producer.ProducerRecord;
import org.apache.kafka.clients.producer.RecordMetadata;
import org.apache.kafka.common.serialization.StringSerializer;
import java.util.Properties;
import java.util.concurrent.ExecutionException;
import java.util.concurrent.Future;
public class SimpleProducer {
private final KafkaProducer<String, String> producer;
public SimpleProducer(String host, String port) {
String server = host + ":" + port;
Properties properties = new Properties();
properties.setProperty(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, server);
properties.setProperty(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, StringSerializer.class.getName());
properties.setProperty(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG, StringSerializer.class.getName());
this.producer = new KafkaProducer<>(properties);
}
public void produce(String topic, String message) throws ExecutionException, InterruptedException {
ProducerRecord<String, String> record = new ProducerRecord<>(topic, message);
final Future<RecordMetadata> send = this.producer.send(record);
final RecordMetadata recordMetadata = send.get();
System.out.println(recordMetadata);
}
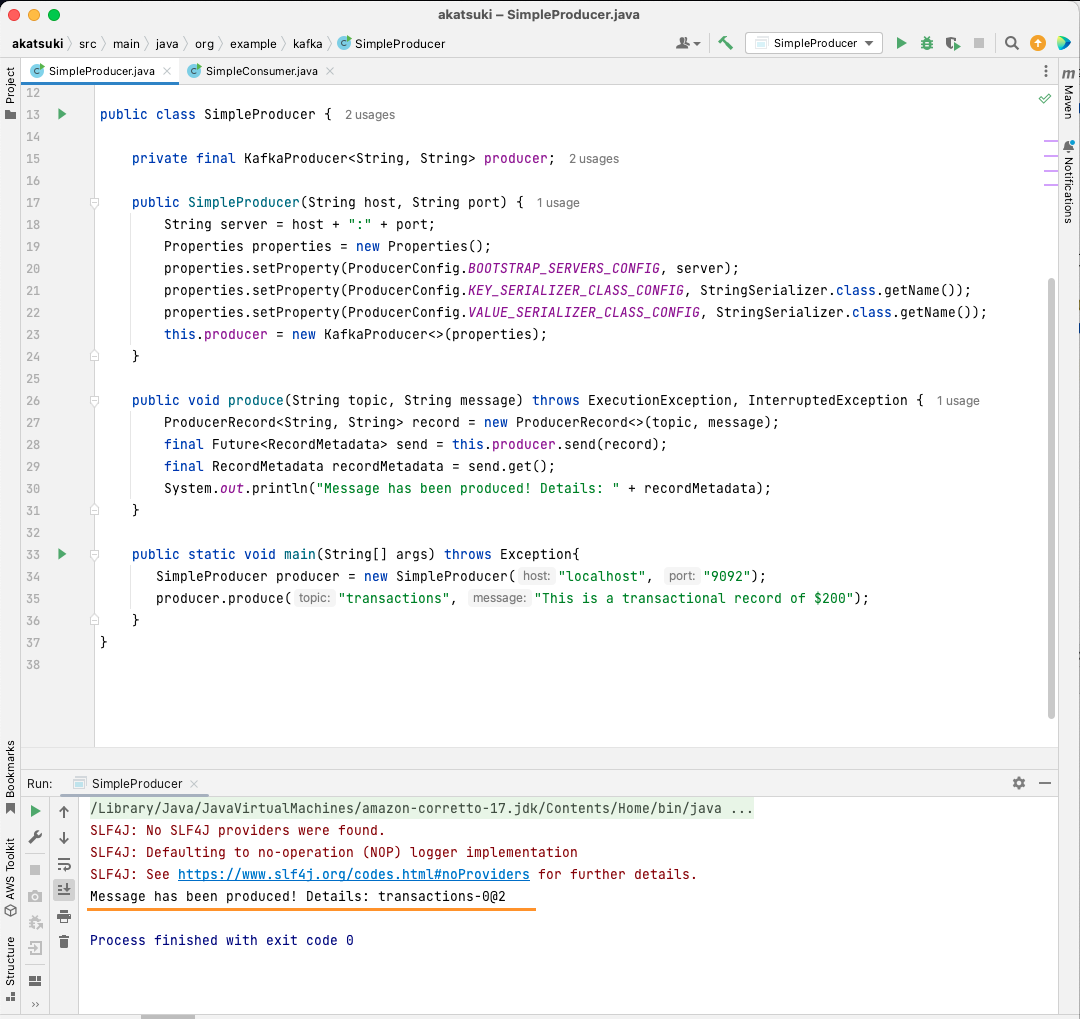
public static void main(String[] args) throws Exception{
SimpleProducer producer = new SimpleProducer("localhost", "9092");
producer.produce("transactions", "This is a transactional record of $200");
}
}
In deze code maak je een SimpleProducer die verbinding maakt met uw Apache Kafka-server op uw lokale computer. Het gebruikt intern de KafkaProducer om tekstberichten over uw onderwerp te produceren.
Creëer Apache Kafka Java-consument
Het is tijd om een Apache Kafka-consument te maken met behulp van de Java-client. Maak een klasse genaamd SimpleConsumer.java. Vervolgens maak je een constructor voor deze klasse, die de org.apache.kafka.clients.consumer.KafkaConsumer. Voor het maken van de consument hebt u de host en poort nodig waarop de Apache Kafka-server draait. Bovendien hebt u de Consumer Group nodig, evenals het onderwerp waarvan u wilt consumeren. Gebruik het onderstaande codefragment:
package org.example.kafka;
import org.apache.kafka.clients.consumer.ConsumerConfig;
import org.apache.kafka.clients.consumer.ConsumerRecords;
import org.apache.kafka.clients.consumer.KafkaConsumer;
import org.apache.kafka.common.serialization.StringDeserializer;
import java.time.Duration;
import java.util.List;
import java.util.Properties;
import java.util.concurrent.atomic.AtomicBoolean;
public class SimpleConsumer {
private static final String OFFSET_RESET = "earliest";
private final KafkaConsumer<String, String> consumer;
private boolean keepConsuming = true;
public SimpleConsumer(String host, String port, String consumerGroupId, String topic) {
String server = host + ":" + port;
Properties properties = new Properties();
properties.setProperty(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG, server);
properties.setProperty(ConsumerConfig.GROUP_ID_CONFIG, consumerGroupId);
properties.setProperty(ConsumerConfig.AUTO_OFFSET_RESET_CONFIG, OFFSET_RESET);
properties.setProperty(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class.getName());
properties.setProperty(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class.getName());
this.consumer = new KafkaConsumer<>(properties);
this.consumer.subscribe(List.of(topic));
}
}Net als bij de Kafka Producer neemt de Kafka Consumer ook een Properties-object in zich op. Laten we eens kijken naar alle verschillende ingestelde eigenschappen:
- BOOTSTRAP_SERVERS_CONFIG vertelt de consument waar de Apache Kafka-server draait
- De consumentengroep wordt vermeld met behulp van de GROUP_ID_CONFIG
- Wanneer de consument begint te consumeren, kunt u met AUTO_OFFSET_RESET_CONFIG aangeven hoe ver terug u berichten wilt gaan consumeren
- KEY_DESERIALIZER_CLASS_CONFIG vertelt de consument het type berichtsleutel
- VALUE_DESERIALIZER_CLASS_CONFIG vertelt het consumententype van het daadwerkelijke bericht
Aangezien u in uw geval tekstberichten zult consumeren, zijn de deserialisatie-eigenschappen ingesteld op StringDeserializer.class.
Je zult nu de berichten van je onderwerp consumeren. Om het simpel te houden, drukt u het bericht af naar de console zodra het bericht is verbruikt. Laten we eens kijken hoe u dit kunt bereiken met behulp van de onderstaande code:
private boolean keepConsuming = true;
public void consume() {
while (keepConsuming) {
final ConsumerRecords<String, String> consumerRecords = this.consumer.poll(Duration.ofMillis(100L));
if (consumerRecords != null && !consumerRecords.isEmpty()) {
consumerRecords.iterator().forEachRemaining(consumerRecord -> {
System.out.println(consumerRecord.value());
});
}
}
}Deze code zal het onderwerp blijven peilen. Wanneer u een consumentendossier ontvangt, wordt het bericht afgedrukt. Test uw consument in actie met behulp van een hoofdmethode. U start een Java-toepassing die het onderwerp blijft gebruiken en de berichten blijft afdrukken. Stop de Java-toepassing om de consument te beëindigen.
package org.example.kafka;
import org.apache.kafka.clients.consumer.ConsumerConfig;
import org.apache.kafka.clients.consumer.ConsumerRecords;
import org.apache.kafka.clients.consumer.KafkaConsumer;
import org.apache.kafka.common.serialization.StringDeserializer;
import java.time.Duration;
import java.util.List;
import java.util.Properties;
import java.util.concurrent.atomic.AtomicBoolean;
public class SimpleConsumer {
private static final String OFFSET_RESET = "earliest";
private final KafkaConsumer<String, String> consumer;
private boolean keepConsuming = true;
public SimpleConsumer(String host, String port, String consumerGroupId, String topic) {
String server = host + ":" + port;
Properties properties = new Properties();
properties.setProperty(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG, server);
properties.setProperty(ConsumerConfig.GROUP_ID_CONFIG, consumerGroupId);
properties.setProperty(ConsumerConfig.AUTO_OFFSET_RESET_CONFIG, OFFSET_RESET);
properties.setProperty(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class.getName());
properties.setProperty(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class.getName());
this.consumer = new KafkaConsumer<>(properties);
this.consumer.subscribe(List.of(topic));
}
public void consume() {
while (keepConsuming) {
final ConsumerRecords<String, String> consumerRecords = this.consumer.poll(Duration.ofMillis(100L));
if (consumerRecords != null && !consumerRecords.isEmpty()) {
consumerRecords.iterator().forEachRemaining(consumerRecord -> {
System.out.println(consumerRecord.value());
});
}
}
}
public static void main(String[] args) {
SimpleConsumer simpleConsumer = new SimpleConsumer("localhost", "9092", "transactions-consumer", "transactions");
simpleConsumer.consume();
}
}
Wanneer u de code uitvoert, zult u zien dat deze niet alleen het bericht verbruikt dat is geproduceerd door uw Java-producent, maar ook de berichten die u hebt geproduceerd via de Console Producer. Dit komt doordat de AUTO_OFFSET_RESET_CONFIG eigenschap is ingesteld op earliest.
Terwijl SimpleConsumer actief is, kunt u de consoleproducent of de SimpleProducer Java-toepassing gebruiken om verdere berichten over het onderwerp te produceren. Je zult zien dat ze worden verbruikt en afgedrukt op de console.
Voldoe aan al uw behoeften aan datapijplijnen met Apache Kafka
Met Apache Kafka kunt u met gemak al uw vereisten voor datapijplijnen afhandelen. Met de installatie van Apache Kafka op uw lokale computer kunt u alle verschillende functies van Kafka verkennen. Bovendien kunt u met de officiële Java-client efficiënt schrijven, verbinding maken en communiceren met uw Apache Kafka-server.
Apache Kafka is een veelzijdig, schaalbaar en zeer performant datastreamingsysteem en kan echt een game changer voor je zijn. U kunt het gebruiken voor uw lokale ontwikkeling of het zelfs integreren in uw productiesystemen. Net zoals het eenvoudig is om lokaal in te stellen, is het instellen van Apache Kafka voor grotere applicaties geen grote taak.
Als u op zoek bent naar platforms voor datastreaming, kunt u kijken naar de beste streaming dataplatforms voor real-time analyse en verwerking.







